A couple of years ago I got a task of writing a module for pricing gamma swaps. I found the task quite difficult, as all I got to base on was an Excel spreadsheet with formulas that were clearly wrong and the few sources on the Internet that I found lacked details. This post (and maybe the next) describes things I learned at that time. Please keep in mind that I am not a quant – just a software guy, so it’s possible I got some of this wrong, maybe all. If you think this is the case please enlighten me in the comments.
One technique for solving problems is to find a practice problem – something easier, but similar enough that going through the exercise gives confidence that the method is sound and serves as a stepping stone to the more difficult one. In case of gamma swaps that simpler problem is pricing of variance swaps.
Variance swaps are financial instruments that are bets about the future observed variance of a price of an underlying asset. The parties that enter the contract observe the price 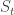 of the underlying at regular intervals
of the underlying at regular intervals  , i.e. at times
, i.e. at times
 ,
,
where  is the life of the contract. Then they calculate the value
is the life of the contract. Then they calculate the value 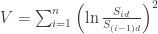 and settle the bet based on that value as compared to some predetermined “strike” value set in the contract. When pricing such contract the question is what is the fair value of the strike, i.e. what is the best prediction of it in the future based on what market tells us right now.
and settle the bet based on that value as compared to some predetermined “strike” value set in the contract. When pricing such contract the question is what is the fair value of the strike, i.e. what is the best prediction of it in the future based on what market tells us right now.
To answer this question suppose that the underlying price process is the geometric Brownian motion 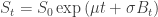 , where
, where 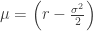 ,
,  is the risk-free interest rate and
is the risk-free interest rate and 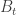 is the standard Brownian motion. Substituting that into the formula for
is the standard Brownian motion. Substituting that into the formula for  yields
yields

Taking the expectation on both sides we get
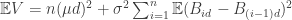
(recall that 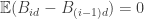 ). Since
). Since 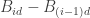 has the same distribution as
has the same distribution as 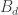 and hence
and hence 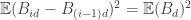 for all
for all 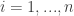 we get
we get
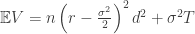
Now there is something I still don’t understand: in the pricing the first component is ignored – assumed equal to zero. Since typically 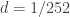 year maybe indeed the value
year maybe indeed the value 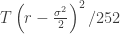 is small enough to not matter.
is small enough to not matter.
Anyway, whatever the rationale for ignoring that term is, as it was easy to guess the fair value of the variance swap strike is closely related to  . The value of can be obtained from option prices as implied volatility, but the problem is this way we actually get a different one for each strike. However, there is an interesting identity that provides a reasonable way to obtain a single number estimate for from (interpolated) market option prices. Namely suppose that
. The value of can be obtained from option prices as implied volatility, but the problem is this way we actually get a different one for each strike. However, there is an interesting identity that provides a reasonable way to obtain a single number estimate for from (interpolated) market option prices. Namely suppose that 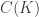 and
and  are the prices of European call and put options with strike price
are the prices of European call and put options with strike price  given by the Black-Scholes formula and
given by the Black-Scholes formula and 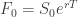 . Then the following identity holds:
. Then the following identity holds:
(I) 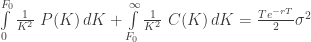
This way by interpolating (and extrapolating as needed) the actual market values of and we can get estimates of the integrals and after multiplying by 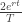 we know what we can expect should be.
we know what we can expect should be.
The rest of this post is about how to verify the identity above with Maxima Computer Algebra System (CAS).
Read the rest of this entry »


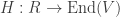
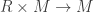
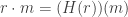

 and
and  . Let
. Let 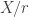 be the set of equivalence classes of this relation and
be the set of equivalence classes of this relation and 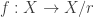 be the projection that maps
be the projection that maps  to it’s equivalence class i.e.
to it’s equivalence class i.e. 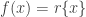 . Then a natural way to define a topology on
. Then a natural way to define a topology on 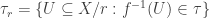 . Note that
. Note that 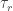 is the strongest topology on
is the strongest topology on  is continuous.
is continuous. , where
, where  is any set. Then the collection
is any set. Then the collection 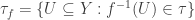 is a topology on
is a topology on 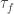 is the strongest topology on
is the strongest topology on 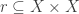 as
as 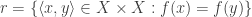 then
then  and the quotient topology defined by that relation is
and the quotient topology defined by that relation is 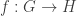 between groups
between groups  and
and 
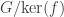 and the image
and the image 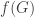 .
.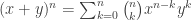 .
.  which probably requires some explanation.
which probably requires some explanation.  symbol is defined as an operator that expects a list as its argument (see the
symbol is defined as an operator that expects a list as its argument (see the 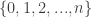 where
where  is a natural number. Functions in ZF set theory are sets of
is a natural number. Functions in ZF set theory are sets of 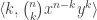 syntax. Now what does that mean that
syntax. Now what does that mean that 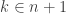 ? The natural numbers in ZF set theory are defined so that zero is the empty set and for
? The natural numbers in ZF set theory are defined so that zero is the empty set and for 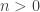 we have
we have 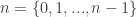 . Hence, the notation
. Hence, the notation 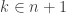 means that
means that 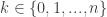 .
. 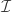 be the set of ideals of some commutative ring and
be the set of ideals of some commutative ring and 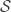 be the set of prime ideals (i.e. the spectrum) of that ring. As it turns out the collection
be the set of prime ideals (i.e. the spectrum) of that ring. As it turns out the collection 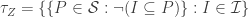 is then a topology, called Zariski topology. The carrier of this topology is
is then a topology, called Zariski topology. The carrier of this topology is 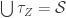 and the closed sets are of the form
and the closed sets are of the form 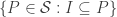 for
for 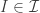 . So this notion belongs to algebraic topology but unlike for the topological groups or rings the topological structure is completely derived from the algebraic structure. Each ring has its Zariski topology.
. So this notion belongs to algebraic topology but unlike for the topological groups or rings the topological structure is completely derived from the algebraic structure. Each ring has its Zariski topology.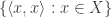 is closed in the product topology on
is closed in the product topology on 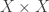 , the
, the 